












In this blog, you will learn about how to scrape Twitter information without using Twitter API or without using a single line of code.
You can use a web scraping tool, for extracting information from Twitter. Web scraping tool allows you to fetch all the data from a website such as Twitter, as it replicates human interaction with a webpage.
You can easily extract Tweet from a handler, tweets with specific hashtags, tweets posted over a certain time window, and so on. Simply copy the URL of your desired webpage and put it into the web scraping tool built-in browser. You will be able to develop a crawler from the initial concept with just a few point-and-clicks.
Once the extraction is finished, you will be able to export the information into excel sheets, CSV, HTML, SQL, or you can also feed it into your database.
Installation
You can execute “twint” inside the docker, also it is possible to install it directly onto your PC using three options.
Git:
git clone https://github.com/twintproject/twint.git cd twint pip3 install . -r requirements.txt
Pip:
pip3 install twint or pip3 install --user --upgrade git+https://github.com/twintproject/twint.git@origin/master#egg=twint
Pipenv:
pipenv install git+https://github.com/twintproject/twint.git#egg=twint
Usage:
After installing “twint” you can scrape your tweets and save the conclusion in a .csv file using the following command.
twint -u username -o file.csv --csv
After execution, the result will be displayed as follows:

You can also use other options for executing with “twint”
# Display Tweets by verified users that Tweeted about Trevor Noah. twint -s "Trevor Noah" --verified # Scrape Tweets from a radius of 1 km around the Hofburg in Vienna export them to a csv file. twint -g="48.2045507,16.3577661,1km" -o file.csv --csv # Collect Tweets published since 2019-10-11 20:30:15. twint -u username --since "2019-10-11 21:30:15" # Resume a search starting from the last saved tweet in the provided file twint -u username --resume file.csv
Docker is used to run “twint”, but if you want to install it directly on your PC, you have a few options:
Twint-search is a good UI for searching your tweets. You will learn how to scrape tweets with Docker, save them to Elasticsearch, then explore the result with twint-search in the next step.
To begin, clone the twint-docker repository as follows:
git clone https://github.com/twintproject/twint-docker cd twint-docker/dockerfiles/latest
Finally, it becomes possible to spin up the docker containers
docker pull x0rzkov/twint:latest docker-compose up -d twint-search elasticsearch
Once everything is fully operational, use the following command to scrape tweets from a person and save them to a.csv file:
ocker-compose run -v $PWD/twint:/opt/app/data twint -u natterstefan -o file.csv --csv
The task’s output would be stored in the $PWD/twint mounted directory. Which is essentially the twint subfolder’s current path.
To complete the command, the number of tweets from the given account must be reached. With ls -lha./twint/file.csv, you should be able to analyze the data once it’s finished.
With docker-compose run -v $PWD/twint:/opt/app/data twint, you may now run any supported twint command.
Twint-search allows exploring tweets
We stored the findings in a.csv file in the earlier quote. However, the results can also be saved in Elasticsearch.
To begin, open docker-compose.yml in your preferred editor (mine is VSCode) and solve the current CORS problem until my pull request is merged.
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:${ELASTIC_VERSION}
container_name: twint-elastic
environment:
- node.name=elasticsearch
- cluster.initial_master_nodes=elasticsearch
- cluster.name=docker-cluster
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=${ELASTIC_JAVA_OPTS}"
+ - http.cors.enabled=true
+ - http.cors.allow-origin=*
Get ready to start the app
# start twint-search and elasticsearch docker-compose up -d twint-search elasticsearch
Save the results into Elasticsearch
docker-compose run -v $PWD/twint:/opt/app/data twint -u natterstefan -es twint-elastic:9200
Now, you can open http://local:3000 and it will display:
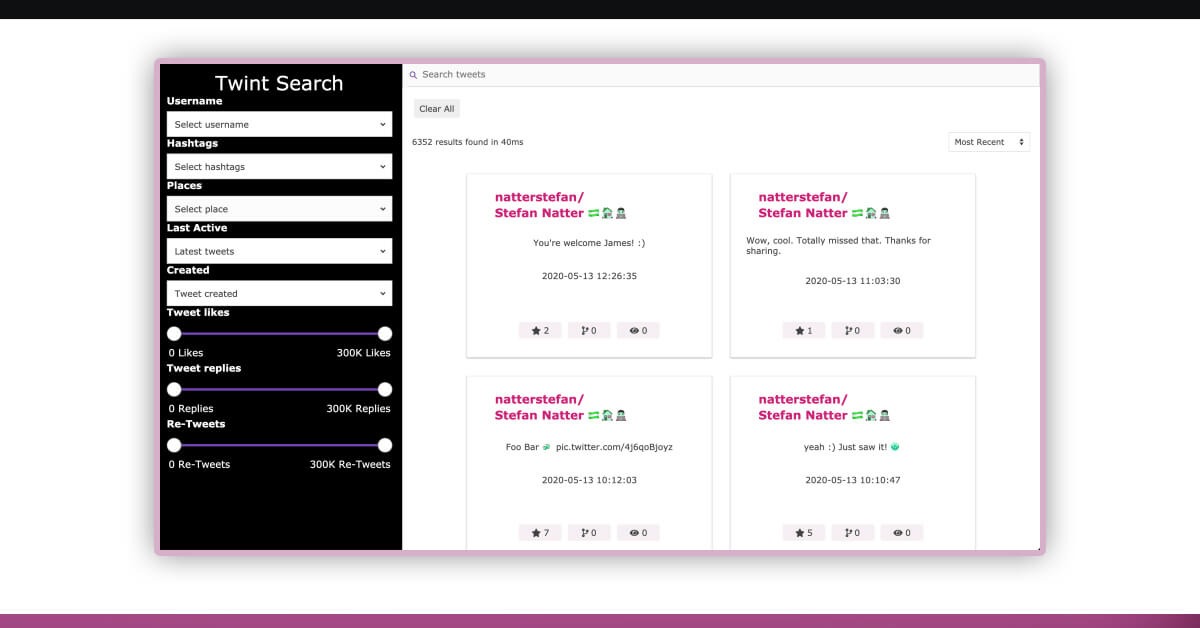
You can also explore more tweets:
Contact Scraping Intelligence for any queries.
Know more : http://www.websitescraper.com/scrape-tweets-from-twitter-using-profiles-without-using-twitters-api/






