














To scrape Amazon for book information, you require to first install Beautiful Soup library. The finest way of installing BeautifulSoup is through pip, so ensure you have a pip module installed.
!pip3 install beautifulsoup4 Requirement already satisfied: beautifulsoup4 in /usr/local/lib/python3.7/site-packages (4.7.1) Requirement already satisfied: soupsieve>=1.2 in /usr/local/lib/python3.7/site-packages (from beautiful)
Importing Required Libraries
It’s time to import the necessary packages that you would use for scraping data from a website as well as visualize that with the assistance of matplotlib, bokeh, and seaborn.
import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns %matplotlib inline import re import time from datetime import datetime import matplotlib.dates as mdates import matplotlib.ticker as ticker from urllib.request import urlopen from bs4 import BeautifulSoup import requests
Extracting Amazon’s Best Selling Books
The URL, which you will scrape is here: https://www.amazon.in/gp/bestsellers/books/ref=zg_bs_pg_'+str(pageNo)+'?ie=UTF8&pg='+str(pageNo) (In case, you are unable to use this link, use parent link). The page row can be adapted to use data for every page. Therefore, to use all these pages, you require to go through all these pages to have the needed dataset, however, first, you require to discover total pages from a website.
For connecting to URL as well as fetching HTML content, these things are necessary:
Describe a get_data function that will input page numbers like an argument,
Outline a user-agent that will assist in bypassing detection as the scraper,
Identify the URL to requests.get as well as pass a user-agent header like an argument,
Scrape content using requests.get,
Extract the detailed page and allocate it to soup variables,
The next step, which is very important is to recognize the parent tag below which all the required data will reside. The data, which we will scrape include:
- Book’s Name
- Author’s Name
- Ratings
- Customer Ratings
- Pricing
The given image indicates where the parent tags are located s well as when you float over that, all the necessary elements get highlighted.
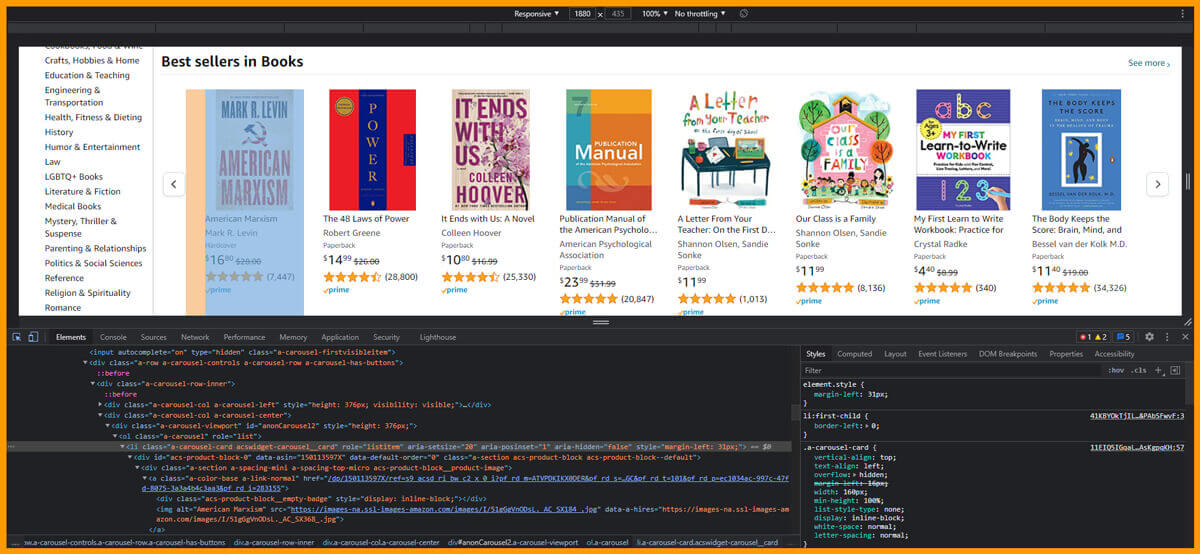
Similar to parents’ tags, you require to get the attributes for author, book name, ratings, customers rated, as well as price. You will need to visit the webpage that you like to extract, choose the attributes as well as right-click on that, and choose inspect element. It will assist you in getting the particular data fields you need to scrape from HTML web pages, as given in the below figure:
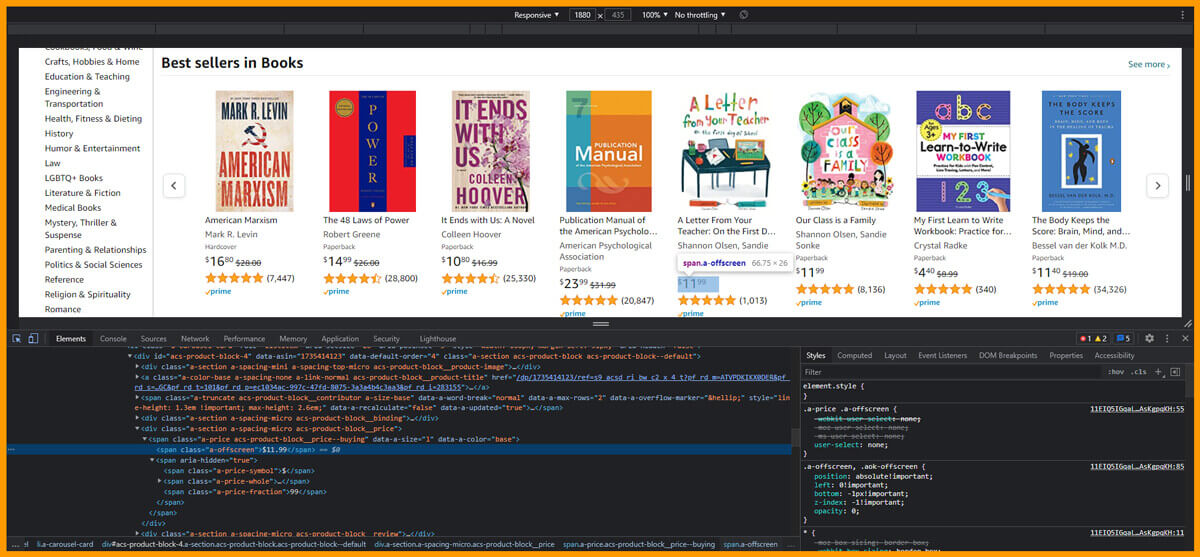
Some authors’ names are not listed with Amazon, therefore you require to apply additional finds for the authors. In the given cell code, you might get nested the if-else conditions for the authors’ names that are to scrape the publication or author names.
no_pages = 2
def get_data(pageNo):
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:66.0) Gecko/20100101 Firefox/66.0", "Accept-Encoding":"gzip, deflate", "Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8", "DNT":"1","Connection":"close", "Upgrade-Insecure-Requests":"1"}
r = requests.get('https://www.amazon.in/gp/bestsellers/books/ref=zg_bs_pg_'+str(pageNo)+'?ie=UTF8&pg='+str(pageNo), headers=headers)#, proxies=proxies)
content = r.content
soup = BeautifulSoup(content)
#print(soup)
alls = []
for d in soup.findAll('div', attrs={'class':'a-section a-spacing-none aok-relative'}):
#print(d)
name = d.find('span', attrs={'class':'zg-text-center-align'})
n = name.find_all('img', alt=True)
#print(n[0]['alt'])
author = d.find('a', attrs={'class':'a-size-small a-link-child'})
rating = d.find('span', attrs={'class':'a-icon-alt'})
users_rated = d.find('a', attrs={'class':'a-size-small a-link-normal'})
price = d.find('span', attrs={'class':'p13n-sc-price'})
all1=[]
if name is not None:
#print(n[0]['alt'])
all1.append(n[0]['alt'])
else:
all1.append("unknown-product")
if author is not None:
#print(author.text)
all1.append(author.text)
elif author is None:
author = d.find('span', attrs={'class':'a-size-small a-color-base'})
if author is not None:
all1.append(author.text)
else:
all1.append('0')
if rating is not None:
#print(rating.text)
all1.append(rating.text)
else:
all1.append('-1')
if users_rated is not None:
#print(price.text)
all1.append(users_rated.text)
else:
all1.append('0')
if price is not None:
#print(price.text)
all1.append(price.text)
else:
all1.append('0')
alls.append(all1)
return alls
The given code cell would do the given functions:
Call get_data function within the for loop,
This for loop would repeat over the functi
From pricing column, remove a comma, rupees symbol, and split that using dot.
In the end, convert all three columns in the float or integer.
df['Rating'] = df['Rating'].apply(lambda x: x.split()[0])
df['Rating'] = pd.to_numeric(df['Rating'])
df["Price"] = df["Price"].str.replace('₹', '')
df["Price"] = df["Price"].str.replace(',', '')
df['Price'] = df['Price'].apply(lambda x: x.split('.')[0])
df['Price'] = df['Price'].astype(int)
df["Customers_Rated"] = df["Customers_Rated"].str.replace(',', '')
dtype: int64
The given graph here is the scatter plot of Authors that bagged customer ratings vs. actual ratings. The following results can be taken after going through the plot.
The Alchemist - Hands down Paulo Coelho's book, is the best-selling book as the ratings and number of clients rated, both are synced.
Ram - Scion of Ikshvaku (Ram Chandra) – written by Amish Tripathi, has average ratings of 4.2 having 5766 customer ratings. Although, a book named The Richest Man in Babylon, written by George S. Clason has nearly similar customer ratings however the overall ratings is 4.5. Therefore, it could be decided that more clients gave a higher ratings with The Richest Man in Babylon.
Conclusion
In this tutorial, we have provided the basic details of doing web scraping using BeautifulSoup as well as how can you make sense out from the data scraped from the web through visualizing that using bokeh plotting library. Another good exercise of taking the step forward while learning data scraping with BeautifulSoup is scraping data from other websites as well as see how you can get insights from that.
If you want to scrape data from Amazon book details then contact Retailgators or ask for a free quote!
source code: https://www.retailgators.com/how-to-scrape-amazon-for-book-information-using-python-and-beautifulsoap.php






With Amazon Data Scraping, it becomes easy to analyze product trends and inspire buyers.
Our Amazon data scraping services will help you get the finest ways of assessing product performance as well as take the necessary steps to do product improvement.GET STARTED NOWPROFESSIONAL AMAZON DATA SCRAPING SERVICES FROM X-BYTEAmazon has an enormous number of listed products that help people do shopping from various categories on one platform.
As Amazon is an e-commerce website, it consists of important data about products and prices.
Our Amazon data scraping services help you find the best ways of evaluating products’ performance and take required actions to do product enhancement.AMAZON PRICE INTELLIGENCEUsing Amazon Price Intelligence, it’s easy to predict the weaknesses of your product and also distinguish the price fluctuations with scraping competitor’s pricing.
We help you with services like:Amazon Price ScrapingAmazon Price AutomationAmazon Price Monitoring Using Data ScrapingResearch shows that 61 % of online shoppers do a price comparison before making any purchase.
We help you understand what your opponents are providing better using Amazon web scraping.AMAZON INVENTORY SCRAPINGYou can track the Amazon inventories in real-time by getting alerts for sold-out or low-stock items.