













Introduction: Why Generic Models Need Domain-Specific Data
Large language models like GPT-4, Claude, and Llama are remarkably capable out of the box. But for enterprise applications that require domain expertise — understanding legal contracts, analyzing financial reports, interpreting medical records, or classifying eCommerce products — generic models fall short. They lack the specialized vocabulary, contextual understanding, and domain-specific reasoning that production applications demand.
Fine-tuning bridges this gap. By training a pre-trained model on domain-specific data, you can dramatically improve its performance on your use case. The challenge is not the fine-tuning process itself — frameworks like LoRA, QLoRA, and full fine-tuning are well-documented. The bottleneck is the data.
Building high-quality, domain-specific training datasets at the scale needed for effective fine-tuning is the single biggest challenge AI teams face. Web scraping provides the most efficient and scalable solution.
What Makes a Good Fine-Tuning Dataset?
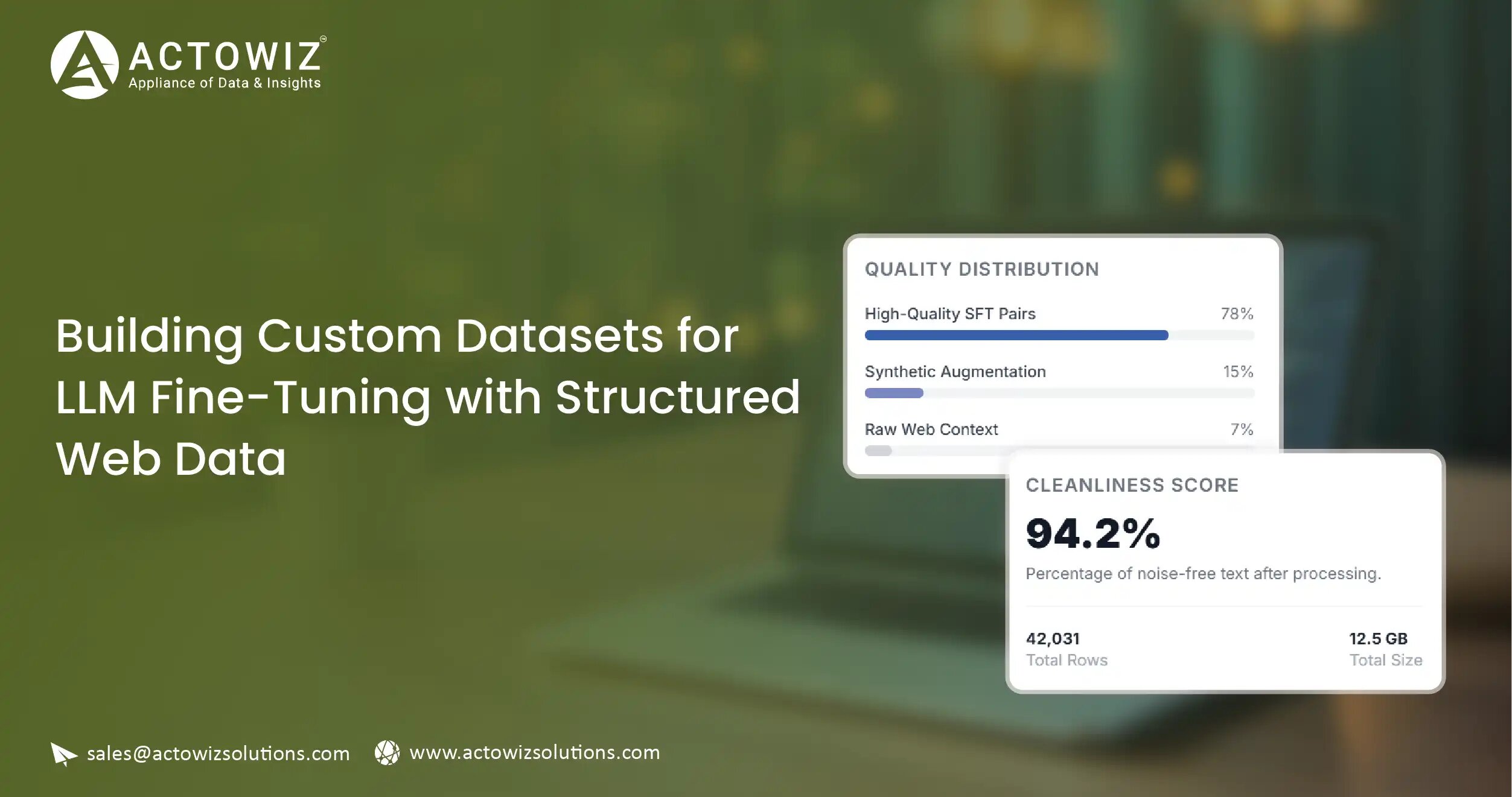
Domain relevance: Data must come from sources that use the same vocabulary, style, and concepts your model needs to learn. Legal fine-tuning requires legal text, not Wikipedia articles about law.
Quality over quantity: For fine-tuning, 10,000 high-quality examples often outperform 1,000,000 noisy ones. Data must be clean, well-formatted, and accurately labeled.
Instruction-response pairs: Modern fine-tuning often uses instruction-response format. Web data needs to be transformed into this format through careful post-processing.
Diversity within domain: Data should cover the full range of scenarios your model will encounter. A legal model needs contracts, court filings, opinions, and correspondence — not just one document type.
Recency: For domains where information changes (finance, technology, medicine), training data must be fresh to prevent model outputs from being outdated.
Web Scraping Strategies for Fine-Tuning DataData
Strategy 1: Domain-Specific Text Corpora
Scrape large volumes of text from authoritative sources in your domain. For financial fine-tuning: SEC filings, earnings call transcripts, analyst reports, financial news. For legal: court opinions, contract databases, legal commentary. For eCommerce: product descriptions, reviews, category taxonomies. For healthcare: medical journals, clinical guidelines, patient forums (with PII removed).
Strategy 2: Question-Answer Pair Generation
Many web sources naturally contain Q&A pairs that can be directly used for instruction fine-tuning. Stack Overflow for technical domains, Reddit AMAs for various topics, Quora for general knowledge, and domain-specific forums all provide questions paired with community-vetted answers.
Strategy 3: Structured Data for Classification
eCommerce product listings with category labels, review datasets with star ratings, news articles with topic tags — these provide naturally labeled data for classification fine-tuning without manual annotation.
Strategy 4: Comparison and Preference Data
For RLHF (Reinforcement Learning from Human Feedback) fine-tuning, you need examples of preferred vs non-preferred outputs. Product comparison pages, review sites with ranked options, and forums with upvoted vs downvoted answers provide this preference signal at scale.
Data Quality Pipeline for Fine-Tuning
Source selection: Identify the 20-50 most authoritative and relevant sources for your domain. Quality of sources directly determines quality of your model.
Extraction and cleaning: Scrape raw content, then remove boilerplate (navigation, ads, footers), fix encoding issues, and standardize formatting.
Deduplication: Remove exact and near-duplicate content. Duplicate training data causes models to memorize rather than generalize.
Quality filtering: Apply automated quality checks including minimum length, language detection, coherence scoring, and domain relevance classification.
Format transformation: Convert cleaned text into instruction-response pairs, chat format, or completion format depending on your fine-tuning approach.
PII redaction: Automatically detect and remove personal information. Essential for compliance and prevents your model from memorizing private data.
Bias audit: Analyze the dataset for demographic, geographic, and topical biases. Implement mitigation strategies where needed.
Version control and documentation: Track every processing step for reproducibility. Document sources, cleaning rules, and quality metrics.
Scale Guidelines: How Much Data Do You Need?
LoRA / QLoRA (parameter-efficient)
Typical Dataset Size: 1K–50K examples
Web Scraping Scale: 50K–500K raw records (before filtering)
Full fine-tuning (7B model)
Typical Dataset Size: 50K–500K examples
Web Scraping Scale: 500K–5M raw records
Full fine-tuning (70B model)
Typical Dataset Size: 500K–5M examples
Web Scraping Scale: 5M–50M raw records
RLHF preference data
Typical Dataset Size: 10K–100K comparisons
Web Scraping Scale: 100K–1M raw comparison pairs
Continued pre-training
Typical Dataset Size: 1B–100B tokens
Web Scraping Scale: Massive web corpus
Case Study: Legal AI Company Builds 2M Record Training Corpus
A legal technology startup needed to fine-tune a language model for contract analysis. Their existing dataset of 15,000 manually annotated contracts was insufficient for the accuracy their enterprise clients demanded.
Actowiz built a pipeline scraping court filings, publicly available contracts, legal commentary, and regulatory documents from 80+ sources. After cleaning, deduplication, and quality filtering, we delivered 2 million structured legal text records in instruction-response format.
Result: The fine-tuned model’s contract clause extraction accuracy improved from 81% to 96%, and the company closed three enterprise deals within the quarter citing the accuracy improvement as the deciding factor.
FAQs
1. Can you create instruction-response pairs from scraped data?
Yes. We transform raw web content into instruction-response format as part of our data processing pipeline. This includes generating questions from headings, creating summarization pairs, and structuring Q&A forum data into chat format.
2. How do you handle copyright for training data?
We scrape publicly accessible content and provide guidance on usage rights. Our compliance team maintains an updated database of source-specific terms of service. We recommend clients consult legal counsel for their specific fine-tuning use case.
3. Can you provide data in Hugging Face format?
Yes. We deliver datasets in standard formats including Hugging Face datasets format, JSONL, CSV, and Parquet. We support SFT, DPO, and RLHF data formats.
4. What domains have you built fine-tuning datasets for?
Legal, financial services, eCommerce product intelligence, healthcare, real estate, recruitment, and customer service. Each domain requires different source strategies and quality standards.
Read More>>
https://www.actowizsolutions.com/custom-datasets-llm-fine-tuning-structured-web-data.php
Originally published at https://www.actowizsolutions.com




All of these around each other form a perfect combination and are figured only in Indian foods.The secret of Indian food's delicious flavor is its rich spices which have been used for decades and spread across the world.
In India, we have multiple Online Masala Store that make your food taste great.With delicious fragrance they flatter our smell, tongue with unique taste and eyes with vibrant colours.
Curry powder, ground spices, and other mixed powders hold a significant flavor and aroma stance.
To make masala ingredients two possible ways are there.One is buy some natural ingredients, whole spices, give them a good whiz in your mixer or food processor, and proportion them out.
Another way is purchase packed masalas withAachi has become a household name due to its great quality products that cater to ordinary people.
Aachi masala is a famous brand of spices, known for its pureness, sweetness, aroma, flavor and good taste as well.

Temperature is often an important radio control cars aspects.
It is preferably to get an infrared thermometer to measure temperatures overcome not work specified for each component (Lipo, ESC and motor).
If you do not have a thermometer, and as home rule, everything should go down to a temperature that can touch it with your fingers for 5 seconds without burning or discomfort.One way to reduce consumption, and therefore the temperature of the components, download the "timming" in the ESC.
It should discard those that are cool packs when held.
A loaded pack should be between 4.1 and 4.2 V per cell, on the other hand, if the voltage is less than 3.8 V per cell with nothing connected except the voltmeter will have to recharge the battery before you leave.
That is, if our Lipo charger supports must be programmed to limit the voltage does not exceed this value.We should never download the Lipo less than 3V per cell, ie cutting the ESC must be at least 6V for two cells in series, 9V for 3, and 12 for 4 cells in series.

Make Video Marketing Your Best Friend With This AdviceVideo showcasing is an energizing and scaring field.
The counsel beneath is intended to start your imagination in advertising your business through recordings.Google search stories are an amazing method to keep yourself off the camera while as yet making video advertising which is viable.
You look for your locales and show the reality where they can be discovered, who is referencing them and what they contain, enabling individuals to discover what you’re about.Try not to accept that the salesmen at you organization are the ones that will glance best before the camera.
No one needs to realize that your organization representative is janitor or secretary.Ensure that you develop an association with your crowd.
Anything faked inside the video, be it, your background or your aura, will perplex them.
On the off chance that you need them to accept what you’re attempting to let them know, be straightforward, straightforward and put on a show of being warm and inviting.Also Visit-Best Video Marketing CompanyItem makers or affiliates ought to make recordings demonstrating how the item can be utilized in elective manners.