







Natural Language Understanding is a building block of intelligent dialog systems, letting machines interpret human input accurately and in context. Intent classification lies at its heart, determining what users want to achieve alongside entity extraction to capture primary details. Together, these algorithms extract semantic meaning from text, enabling dialog systems to decide the most appropriate action to perform next.
Businesses building such systems require partnering with a specialized service provider. A leading company offers domain-trained annotators, quality-controlled workflows, and robust datasets. It helps ensure that intent and entity labels are precise and consistent. They also implement multilingual support, scalability, and compliance frameworks that in-house teams often struggle to maintain. Service providers help accelerate the development of reliable NLU models by supplying high-quality annotated data. It ultimately allows companies to deliver dialog systems that feel more responsive, natural, and human-like.
What is Text Intent Classification in NLP?
Text intent classification is integral to natural language processing (NLP). It enables machines to comprehend and respond to human language. Intent classification, also named as intent recognition or detection, determines the intention or goal behind a given text or spoken language. It incorporates categorizing user inputs into predefined categories. Each category represents a defined intent or purpose. This supports recognizing a user's goal from their text input and maps it to a predefined label, such as book_flight or check_balance.
For instance, if someone types a query like "show me my current account balance," the system must comprehend that it is a balance inquiry, not a fund transfer or a new account request. NLP techniques lead this by evaluating free-form text and assigning it to the correct intent label, allowing dialog systems to respond with the right action.

What are the Top Methods of Intent Classification?
Intent classification has evolved from rigid, hard-coded scripts to flexible, self-adapting models, with each approach offering its own strengths.
- Rule-Based and Pattern Matching
Rule-based systems are effective for quick demos or narrow domains. Intents are defined using keyword lists or regex patterns.
Example
- INTENT: PASSWORD_RESET
Patterns: "reset password," "forgot my password," "recover account"
This approach works well for prototypes or legacy workflows, but becomes brittle with even a slight variation, like "Help me get back into my account," which can cause the system to miss the intent.
- Classical ML Models
In text intent classification, classical ML models carried most of the load before transformers came along. Text was categorized into features like TF-IDF scores, n-grams, or part-of-speech tags, which were then passed to algorithms such as Support Vector Machines (SVMs) or Random Forests.
Pros
- Lightweight.
- Easy to debug.
- Perform well on smaller datasets.
Cons
- Require manual feature engineering.
- Struggle to generalize to messy, real-world text.
While primarily surpassed by deep learning, these models still shine where fast inference and low resource usage matter, such as in embedded systems and edge devices.
- Fine-Tuned Transformers
Modern intent classification counts on transformer models such as BERT. It is simple: begin with a pre-trained model, append a linear classification layer, and fine-tune it with labeled data. Most implementations utilize the output of the [CLS] token, which represents the meaning of the whole sequence, for sentence-level classification.
Why does BERT work so well?
- Captures deep semantic structure
- Learns contextual meaning (e.g., "bank" as a financial institution vs. "bank" of a river)
- Scales effectively with larger datasets.
You will need sufficient annotated samples and GPU resources, but the performance jump in accuracy usually makes it worthwhile.
- LLM-Based Models
Large language models (LLMs) such as GPT offer a practical alternative when labeled data is scarce. With prompt-based intent classification, you can quickly test and deploy without pretraining.
Example prompt:
For example, there is a user query 'Where is my package?' classify the intent as: [order_tracking, cancel_order, return_request]."
LLMs support intent discovery by suggesting new categories based on real-world queries. However, they also have drawbacks, such as latency, higher cost, and occasional inconsistency. To mitigate these, teams often use few-shot examples and structured prompts (e.g., JSON output with strict label sets).
Data Quality Matters
The quality of labeled datasets impacts accuracy irrespective of the labeling approach. Fine-tuned transformers grow on rich annotations, while LLMs still require precise prompt engineering and validation. If your team lacks the bandwidth for annotation, partnering with professional data labeling services can accelerate projects and ensure consistency across domains like text classification, medical imaging, or document processing.
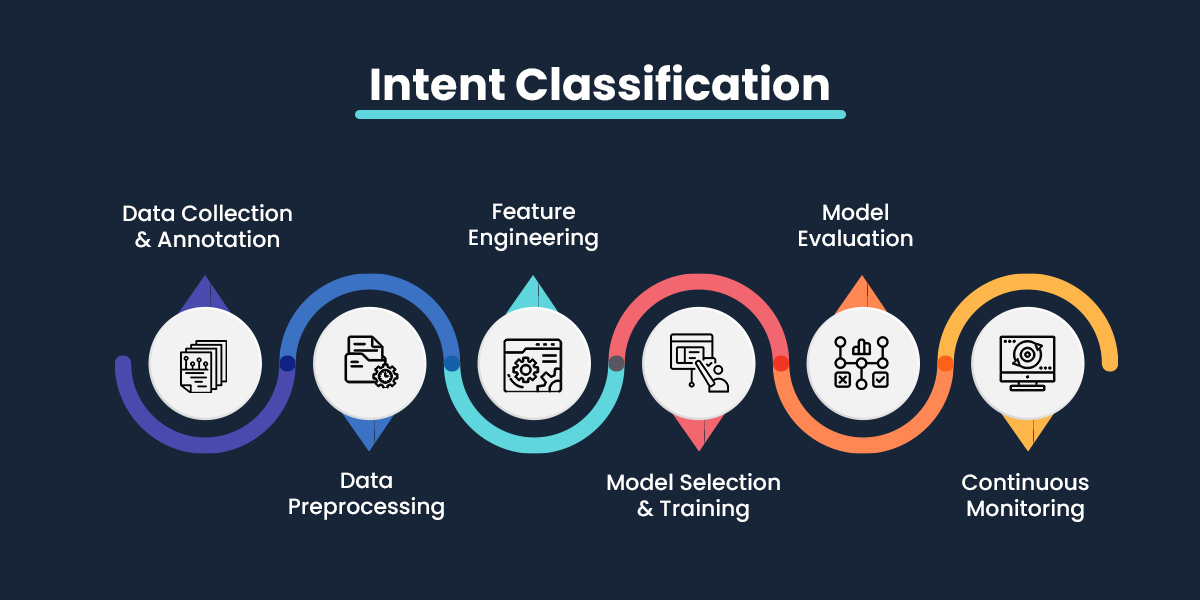
How Does Intent Classification Work?
Intent classification comprises data preprocessing, machine learning algorithms, evaluation, and training. Let's examine how it works and the role of the steps involved in shaping a practical intent classifier.
Understanding the Role of Machine Learning Algorithms
Machine learning algorithms are called the basis of intent classification as they can learn patterns and relationships within data. It allows models to assign an input to the correct intent category.
- Supervised Learning - Intent classification is usually a supervised learning task, where models are trained on labeled datasets with known intent categories.
- Deep Learning - Advanced models such as recurrent neural networks (RNNs), convolutional neural networks (CNNs), and transformer architectures like BERT or GPT achieve state-of-the-art results by capturing rich contextual information in text.
Data Preprocessing and Feature Extraction
Data preprocessing is an imperative step in preparing inputs for intent classification. It emphasizes cleaning and shaping raw text (or speech) into a format that machine learning models can interpret effectively.
Major steps include
- Tokenization - Splitting text into individual units such as words or tokens.
- Stopword Removal - Filtering out common words (e.g., "the," "is") that add little semantic value.
- Lemmatization/Stemming - Reducing words to their base form (e.g., "running" → "run") to handle variations.
- Feature Extraction - Converting text into numerical features, such as TF-IDF vectors or word embeddings (e.g., Word2Vec, GloVe), which serve as model-ready inputs.
Building and Evaluating the Intent Classifier
An intent classifier is trained on a labeled dataset, where each input (text or speech) is paired with its correct intent category. The process typically involves:
- Model Training - It teaches the model to map inputs to intent categories by using the training set.
- Dataset Splitting categorizes data into training, validation, and test, and aims to enable fair performance evaluation.
- Hyperparameter Optimization - Fine-tuning parameters to maximize accuracy while reducing overfitting.
- Cross-Validation - Testing unseen data during training ensures the model generalizes well.
Metrics for Evaluating Text Intent Classifiers
Evaluating an intent classifier demands metrics capturing accuracy and performance on specific intent categories. These measures reveal how well the model meets its goals and highlight areas for improvement.
- Accuracy - The proportion of correctly predicted intents across all examples, offering a general performance snapshot.
- Precision and Recall - Precision reflects how many predicted positives were correct, while recall indicates how many actual positives were successfully identified, which is especially valuable for imbalanced datasets.
- F1-Score - The harmonic mean of precision and recall, providing a balanced view when both metrics are equally important.
Creating High-Quality Datasets for Text Intent Classification
A well-constructed dataset is the groundwork of any effective intent classification system. Creating one requires careful attention to collection, annotation, diversity, and representation to determine robust model performance.
Partnering with a service provider to build high-quality and domain-oriented intent datasets will prove to be a good choice, as you will save time from drafting annotation guidelines to managing large-scale labeling projects.
Data Collection and Annotation
- Data Sources - Gather speech or text samples from channels related to your domain, including industry-specific documents, user queries, and customer support logs.
- Annotation - Employ human annotators to label each instance with the appropriate intent category. This can be done manually, semi-automatically, or with the help of crowdsourcing platforms.
- Guidelines - Provide clear labeling criteria and detailed instructions to maintain annotation consistency across annotators.
Why Diversity and Representation Matter?
- Capturing Edge Cases - The inclusion of unusual and rare queries prepares the model for tackling unexpected inputs.
- Reducing Bias - Diverse datasets lead to reducing bias by exposing the model to different phrasing styles, demographics, and contexts.
- Boosting Real-World Accuracy - A dataset that mirrors fundamental user interactions improves generalization and ensures the classifier performs reliably in production.
Refining Datasets with Data Augmentation
A large and diverse dataset is not feasible, as data augmentation can expand and enrich your training data without starting from scratch. These techniques introduce natural variation while preserving intent and boosting model robustness.
- Prevalent Techniques
- Back-Translation - This technique is based on translating text into another language and back to spawn semantically equivalent alternatives.
- Synonym Replacement - It comprises swapping phrases and words with closer synonyms to augment linguistic variety while preserving meaning.
- Paraphrasing - This helps rewrite sentences manually or with paraphrasing models to bring diversity while maintaining intent.
- Noise Injection - This technique makes it simple to introduce typos, missing words, or grammatical errors to mimic real-world user input.
- Multi-Source Merging - It unites datasets from different channels to broaden coverage of user interactions.
Building an effective dataset is iterative—continuous collection, annotation, and augmentation ensure your intent classifier adapts well to real-world scenarios. Next, we'll look at model selection, feature engineering, and training to turn this data into a high-performing classification system.
Feature Engineering for Intent Classification
Feature engineering is crucial to developing accurate intent classification systems. It focuses on converting raw text into meaningful numerical features that machine learning models can process effectively. Combining preprocessing steps with robust representation techniques can significantly improve classifier performance.
Text Preprocessing
Normalizing and cleaning the data before transforming text into features is recommended.
Standard preprocessing methods include:
- Lowercasing - Standardizes text by treating words equally, regardless of capitalization.
- Tokenization- Splits sentences into individual words or tokens, making them easier to analyze.
- Stopword Removal - This filter removes high-frequency words such as "the," "is, "and" that" that add little value to intent detection.
Word Embeddings and Representations
Once preprocessed, text needs to be represented numerically. Word embeddings map words into dense vectors that capture semantic meaning. Popular methods include:-
- GloVe - This creates embeddings from a word co-occurrence matrix by encoding global statistical information. For instance, it learns that the word “ice” is closer to the word “cold” as compared to “steam” based on word co-occurrence patterns.
- Word2Vec - It learns an embedding by envisioning a word’s surrounding context and captures word similarity. Let’s comprehend with an example “king – man + woman ≈ queen.”
- FastText - Enhances Word2Vec by incorporating subword information, allowing it to understand rare words and morphological variations. Example: FastText can infer meaning for “playfulness” by learning from subwords like “play,” “-ful,” and “-ness.”
Feature Optimization and Dimensionality Reduction
Feature selection helps identify the text data's most relevant features (words or tokens). Dimensionality reduction techniques can be applied to reduce the number of features and computational complexity. Common methods include:
- TF-IDF (Term Frequency-Inverse Document Frequency) - TF-IDF prioritizes words based on their frequency in a document relative to their frequency across all documents. It helps identify important words specific to a document.
- Principal Component Analysis (PCA) - PCA reduces the dimensionality of the data while preserving the most essential information. It can be applied to word embeddings to create more compact representations.
- Feature Engineering with Domain Knowledge - In some cases, domain-specific knowledge can guide feature engineering. You can include keywords or entities highly relevant to your NLP intent classification task.
Conclusion
Intent classification is crucial in modern dialog systems, allowing machines to comprehend human goals and respond accurately. From rule-based methods to advanced fine-tuned transformers and LLM-oriented approaches, techniques are selected based on the domain, scale, and available resources. Amid it, one thing tops the chart across all methods, i.e., diverse, high-quality, and well-annotated datasets are the main determinants of reliability and accuracy. By combining robust data practices with advanced NLP models, organizations can build intent classifiers that understand language and deliver actionable, context-aware responses in real-world applications.




